Applied Artificial Intelligence & its role in an AGI World
I’ve been meaning to write this for a while—an article diving into applied AI and what it could look like in a world dominated by artificial general intelligence (AGI). This idea has been on my mind, especially with critics claiming that the success of today’s AI startups is temporary, arguing that once AGI hits, their technical moats will vanish, leaving them wide open to competition. While I could talk about how these companies might adapt, build strong brands, or leverage non-technical marketplace advantages, I want to focus on the tech itself: will applied AI still hold value in an AGI-dominated world?
So, where do we begin?
Let me begin with a fundamental belief about the impact of artificial intelligence on businesses and workers: it will redefine the nature of work, enabling everyone to shift from being mere executors to becoming architects over their work. We're already witnessing the early signs of this transformation—unsurprisingly in software engineering, the field with the highest proportion of early AI adopters. Tools like Cursor, Windsurf and Aider are enabling engineers to outline their vision and delegate much of the development work to AI assistants Thanks to recent reasoning models and code-specific foundation models like DeepSeek v3, these tools are becoming increasingly accurate, letting engineers focus on optimizing and refining solutions rather than writing every line of code
To see Aider’s LLM Leaderboard, see here: https://aider.chat/docs/leaderboards/
But as AI model intelligence continues to advance, how will these tools and similar vertical agents evolve? Can solutions built on frontier models maintain their competitive tech moat, or will they be overtaken by intelligence-driven advancements? Will innovations in knowledge processing, retrieval, structured workflows, and user experience design continue to hold their relevance?
To answer these questions, we need to define what drives artificial intelligence innovation. Broadly speaking, it falls into two core categories:
- Foundational Innovation: These are groundbreaking advances that refine broad AI capabilities. Landmark papers such as Attention is All You Need, the leap represented by GPT-4, and recent discoveries surrounding inference-time compute scaling laws represent this category.
- Applied Innovation: This is where foundational advances get turned into tools that unlock value for businesses and consumers. Think Cursor and Aider for software development or Exa AI in search. These are systems solving real-world problems by embedding intelligence into specific contexts and workflows.
What is Artificial General Intelligence Anyway?
Let’s talk about AGI. Definitions vary, but here’s one I found on X: AGI is when computers make $100B.
Yeah, let’s run with that.
Before you stop reading—yes, that was a joke. Let’s shift gears and focus on a definition that provides genuine insight. Steve Newman’s description in Defining AGI encapsulates the concept well, describing AGI as:
“AI that can cost-effectively replace humans at virtually all economic activity, implying that they can primarily adapt themselves to the task rather than requiring the task to be adapted to them.”
He further explains with a more intangible definition of AGI, noting that:
“As AI capabilities advance, there will be an inflection point where the impact increases steeply, and most of the things people refer to as ‘AGI’ will occur somewhere close to that inflection point.”
These quotes underpin two pivotal characteristics of AGI:
- Broad Capability: AGI adapts to solve problems across diverse domains without requiring tasks or workflows to be redesigned for it.
- Transformative Impact: As AI progresses, it will reach an inflection point where the economic and societal implications explode, reshaping industries, accelerating scientific breakthroughs, and introducing profound risks and opportunities.
So Where Are We Now? Reasoning Models & Learning to Think
Recent advancements in reasoning models are bringing us closer to the adaptability Newman envisioned. OpenAI’s o1 model marks a major leap forward, designed to think more like humans by spending time deliberating over problems, refining strategies, and learning from mistakes. This shift comes at a perfect time, given the diminishing returns we’ve seen in pre-training scaling since GPT-4.
In benchmark tests, o1 has demonstrated extraordinary performance, rivaling human expertise in challenging tasks across physics, chemistry, and biology. Its achievements in math and coding are particularly impressive: o1 correctly solved 83% of problems in a qualifying exam for the International Mathematics Olympiad (compared to GPT-4’s 13%) and reached the 89th percentile in Codeforces programming contests. While it may lack some features of more general-purpose models like browsing or file handling, o1 sets a new standard for tackling intricate reasoning tasks.
Chain-of-Thought Reasoning
Chain-of-thought reasoning has been around for a while, commonly used as a prompting technique to help language models break problems into smaller, logical steps. This approach mirrors how humans solve complex problems—like writing out the steps for long division instead of doing it mentally. By creating a “tunnel of reason,” chain of thought keeps the model focused and reduces errors.
What makes o1 different is that it doesn’t rely on external prompting. Instead, it’s been trained through reinforcement learning to use chain-of-thought reasoning automatically. When you ask a question with o1 enabled, it lays out its thought process explicitly, making its reasoning transparent. This has proven invaluable in domains like math, science, and coding, where multi-step problem-solving is essential.
Reinforcement Learning and Self-Reflection
Reinforcement learning during training plays a crucial role in enhancing o1's reasoning abilities. Through iterative feedback, the model was taught to explore different strategies using chain-of-thought reasoning, identify and learn from its mistakes, and refine its problem-solving methods over time. This self-reflective process ensures that o1 not only solves problems but also continuously adapts and improves, making it capable of tackling increasingly complex challenges.
This capability is even reflected in o1’s nickname, Strawberry, a playful nod to the challenge of counting the "R’s" in the word "strawberry." Just as identifying every step in a reasoning process can be tricky, o1 excels at breaking down these complexities, making reasoning more precise and efficient.
Example: Tackling the Strawberry Problem
A classic demonstration of o1's capabilities is its approach to the so-called "Strawberry Problem." This challenge highlights the importance of careful reasoning to ensure every step is accurate—akin to counting all the "R’s" in the word "strawberry" without overlooking any. Using chain-of-thought reasoning, o1 systematically breaks the problem into smaller steps, identifies potential errors, and adjusts its approach. This process showcases o1's ability to think critically and reason effectively, outperforming its predecessors that lack advanced reasoning capabilities.
Below is the output from GPT-4o and o1 when attempting to solve the "How many R’s are in the word strawberry?" problem. As shown, GPT-4o incorrectly identifies the answer as 2, while o1 accurately determines the correct answer is 3.
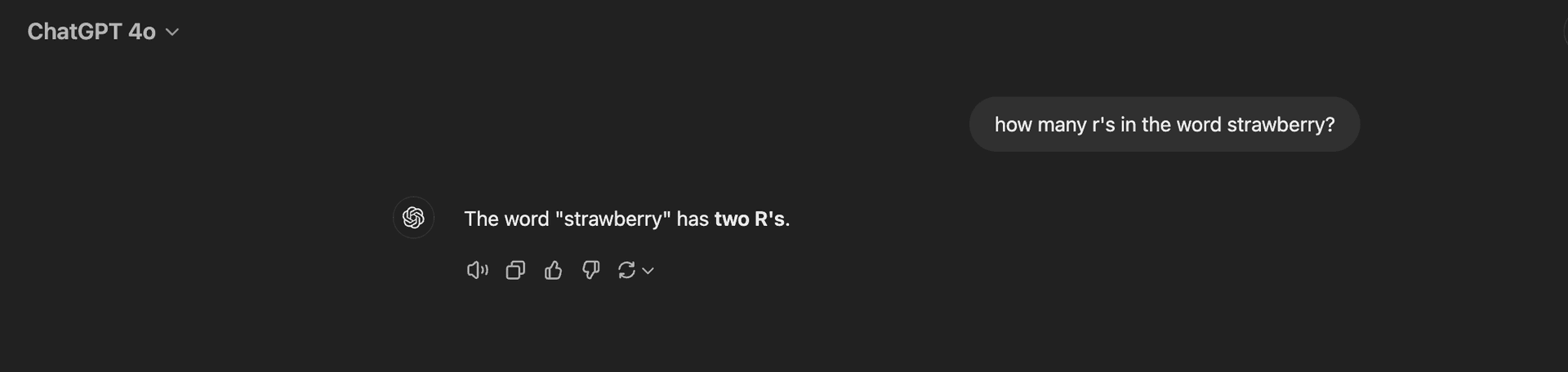
GPT-4o incorrectly identifies the answer as 2.
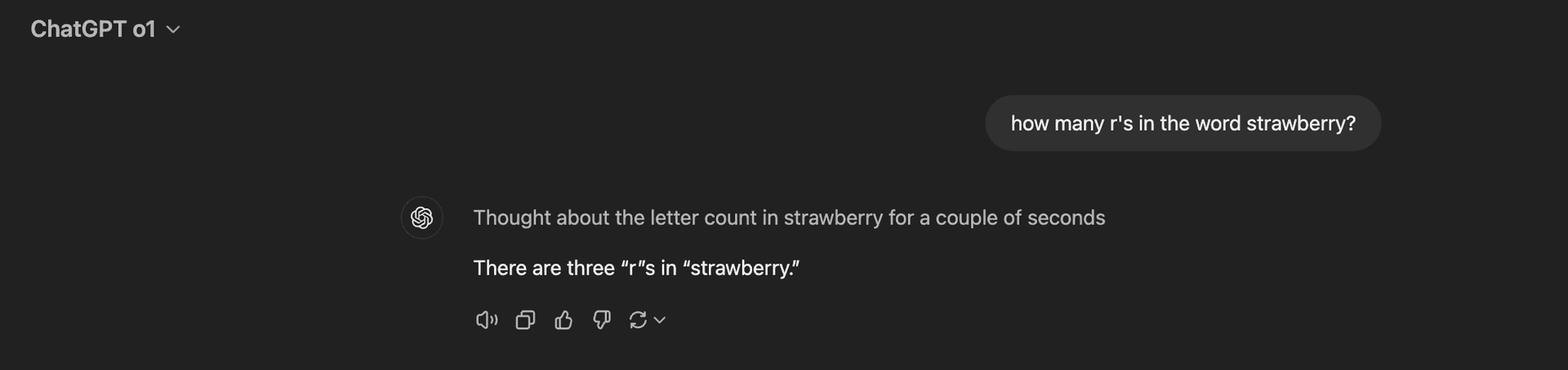
o1 accurately determines the correct answer is 3
Computational Resource Allocation
A defining characteristic of o1 is its innovative approach to computational resource allocation, driven by the recent shift toward scaling compute at test time. Unlike traditional large language models, which dedicate the majority of their resources to pretraining, o1 strategically reallocates computational focus to the fine-tuning and inference phases. This shift is largely a response to the diminishing returns observed in scaling pretraining efforts, which is why we’re no longer seeing models balloon in parameter size as they did prior to the GPT-4o release. Additionally, the scarcity of high-quality data beyond what GPT-4-level models have already been trained on has further limited the effectiveness of brute-force pretraining. In response, AI labs have started augmenting their training pipelines with synthetic data generated by language models themselves, in addition to refining existing datasets.e
Two main strategies have emerged for scaling test-time compute: self-refinement and search against a verifier. While OpenAI hasn’t released many details about how they’ve shifted toward test-time compute, they have briefly mentioned leveraging reinforcement learning to entrench self-reflective, chain-of-thought behaviors at inference time. Despite this, we can infer much about the underlying mechanisms from recent research and open discussions. This Hugging Face blog, in particular, has proven to be a tremendous resource in summarizing recent research in this methodology.
Self-refinement focuses on the model iterating over its outputs, identifying errors, refining its reasoning, and ultimately landing on improved solutions. Search against a verifier takes a different approach by generating multiple candidate answers and using a secondary model or reward mechanism to determine which one is the most accurate. By employing these strategies, o1 efficiently redistributes its computational resources, allowing it to explore a wider range of solutions and reason more deeply at inference time. This has already led to significant performance gains in tasks like the American Invitational Mathematics Examination (AIME), where scaling test-time compute directly boosts accuracy. These advancements highlight the powerful potential of adaptive, test-time resource allocation.
Enter o3: A New Benchmark
Building on the success of o1, OpenAI recently announced its successor, o3, during the 12 Days of Christmas event. While o3 is not yet publicly available and remains in safety testing, its early results are the closest performance to true AGI we’ve seen yet. The model achieved an unprecedented 96.7% score on the AIME 2024, a significant leap from o1’s 83.3%. Additionally, it has demonstrated exceptional performance on PhD-level science questions, achieving an impressive 87.7% accuracy. These advancements signal a new era of capability, solidifying o3 as a transformative step forward in AI reasoning and problem-solving.
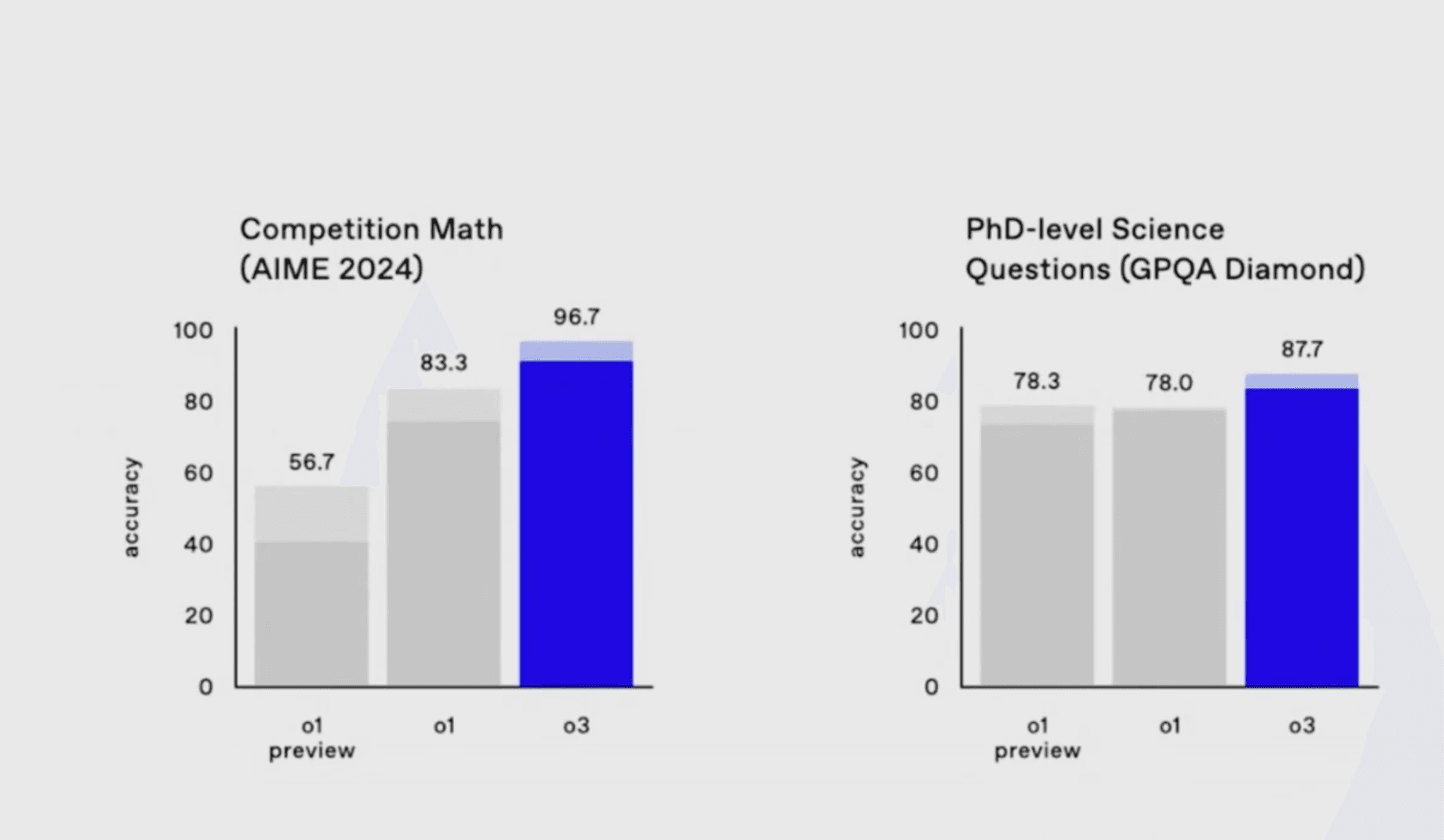
AIME 2023 and GPQA Diamond Results from o1-preview, o1, and o3.
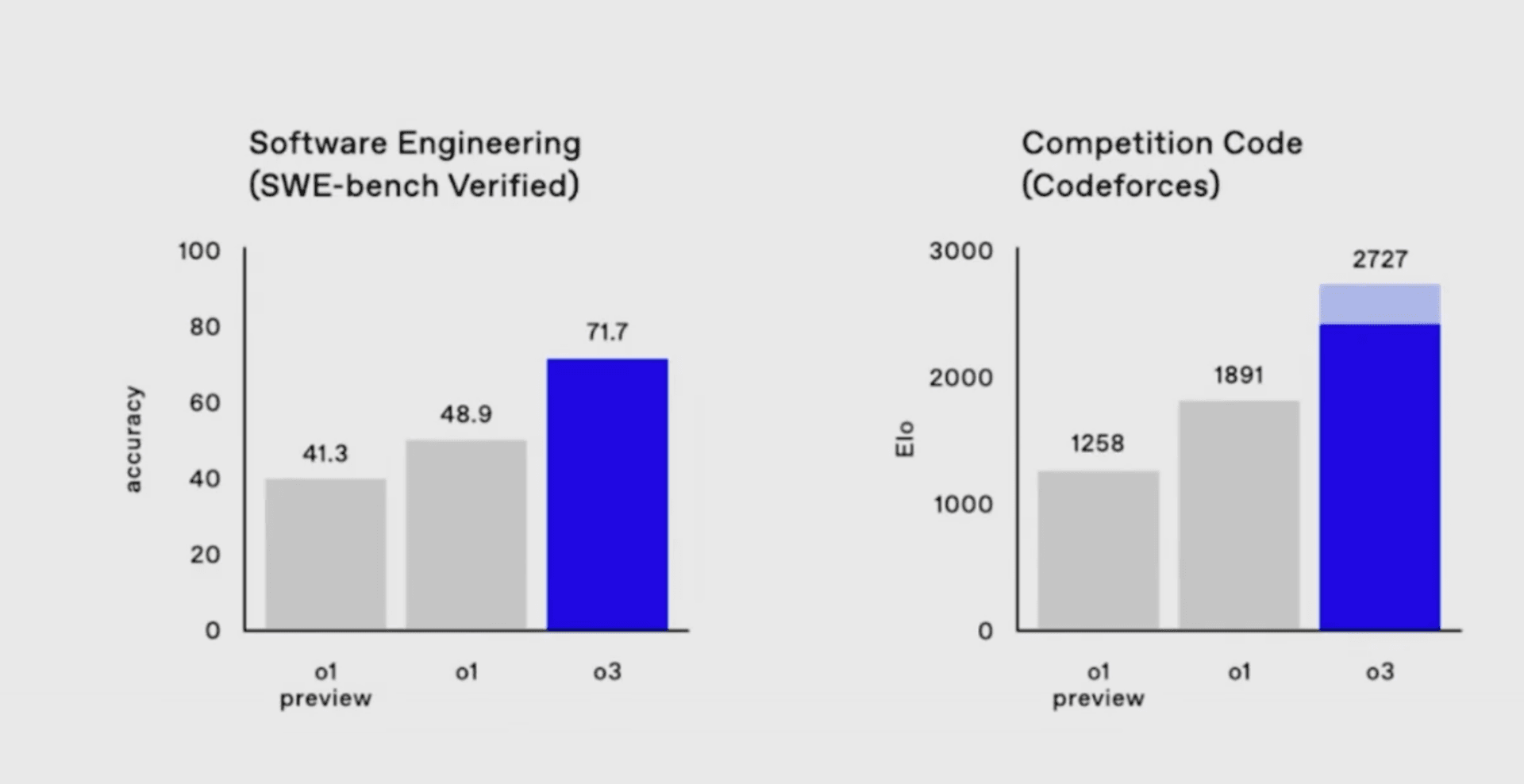
Its performance in software engineering is equally impressive, jumping to 71.7% on the SWE-bench Verified benchmark from o1’s 48.9%.
The Critical Role of Applied AI in an AGI World
The remarkable advancements showcased by reasoning models in adaptability and mirroring human problem-solving bring us closer to Newman’s vision of AGI excelling across a diverse range of economically valuable tasks. These models illustrate how AI can deconstruct complex problems, think critically, and refine its strategies—laying a crucial foundation for human-level intelligence. However, a critical yet often-overlooked nuance lies in the distinction between intelligence and knowledge: the two are not synonymous.
While adaptability and reasoning are key components of intelligence, they alone are insufficient for AGI to reach its full potential. Models like o1 and o3 represent significant advancements, approaching human-level reasoning and problem-solving in impressive ways. Yet, these models are not AGI—and no matter how intelligent they become, their effectiveness ultimately depends on the cooperation between intelligence and contextual knowledge. Without this foundation of domain-specific knowledge, even the smartest models risk producing results that are disconnected from the practical realities of specific workflows and tasks.
Knowledge vs. Intelligence
Knowledge encompasses the structured facts, processes, conventions, and contextual subtleties that define a specific domain or task. It includes understanding how an organization operates, recognizing implicit norms, and accessing specialized datasets or insights that guide effective decision-making. Intelligence, on the other hand, is the capacity to reason, learn, and adapt to novel situations. While intelligence excels at deduction and inference, it is fundamentally reliant on knowledge to operate meaningfully within a given context. Without this foundation, even the most advanced intelligence risks producing outcomes that are misaligned with the complexities and demands of real-world tasks.
Take the following example:
Consider a world-class doctor renowned for their diagnostic skills and medical expertise. Presented with a critically ill patient, they could employ their intelligence to analyze symptoms and propose potential treatments. However, without access to the patient’s medical history—such as allergies, chronic conditions, or prior treatments—their ability to make an accurate diagnosis or recommend a safe course of action would be severely limited. Intelligence alone, no matter how exceptional, must be grounded in domain-specific knowledge to deliver outcomes that are both precise and practical.
Now, let’s consider a practical example more relevant to the current landscape of artificial intelligence by examining Cursor and its potential to scale as model intelligence improves.
Advanced models like OpenAI’s o1 and o3 excel at coding and solving programming challenges, achieving significantly higher accuracy than earlier models like GPT-4o or Claude-3.5-Sonnet. However, these highly intelligent models are no better at adhering to a startup team’s or software engineer’s specific coding preferences—such as conventions for docstrings, commenting styles, programming paradigms, or preferred tech stacks—unless explicitly told about them. This limitation persists even as model intelligence increases because the issue isn’t rooted in raw intelligence but in the absence of accessible, intelligently applied domain-specific knowledge.
This highlights the critical role of applied AI innovation in bridging the gap between intelligence and practical utility. Cursor provides a compelling example: with its .cursorrules feature, teams can encode their specific preferences—such as coding patterns, tech stacks, and heuristics—directly into the system. By embedding this domain-specific knowledge, Cursor ensures that AI models operate in alignment with real-world expectations and workflows, transforming raw intelligence into actionable results.
So What Does This Mean?
If there’s one thing I hope to convey, it’s this: while intelligence is advancing at a remarkable pace, the need for a strong applied AI foundation remains as critical as ever. Whether you’re a business leader, an applied AI startup, an AI engineer, or an aspiring AI practitioner, staying ahead of the curve requires continuous action and preparation. The inevitable inflection point in efficiency gains will reshape industries—but only for those who actively preparing.
For Businesses: Adopt AI Now, Not Later
As I’ve mentioned before, artificial intelligence is empowering people to move from workers to architects of their work. This transformation is already underway, and businesses of all kinds—from traditional brick-and-mortar retailers to fast-moving tech startups—must evolve into AI-first organizations to remain competitive. So, how do you prepare for this shift?
Identify Workflows Ready for AI Disruption
Pinpoint processes that are repetitive, time-intensive, or heavily reliant on outsourced technical expertise. These workflows are ideal for AI-powered, human-in-the-loop augmented systems, with the potential to transition into agentic-driven automation as efficiency and trust in the system mature.
Clarify Your Data Access Strategy
Align resource accessibility with AI workflows and applications, ensuring that the right individuals have access to the appropriate data for the AI solutions they interact with or oversee. This fosters cohesive alignment across access, users, and augmented systems, and agents.
Prepare Your Data Layer
With high-value workflows identified and a data access strategy in place, prioritize preparing your data layer. This foundational layer underlays all AI applications and workflows, ensuring scalability and sustainable development as your needs evolve.
A comprehensive data layer requires unique ingestion pipelines to clean, structure, and prepare both structured and unstructured data for use with LLMs. These pipelines should optimize data for AI consumption while maintaining the necessary latencies for the specific workflows they support. Once the data is preprocessed, advanced tools like vector and graph databases handle much of the heavy lifting—storing, indexing, and enabling efficient retrieval of relevant knowledge. These databases work alongside specialized knowledge and data retrievers to provide accurate and contextually relevant information to both agents and humans.
Implement Observability from Day One
Define clear, quantifiable metrics for success for every workflow you plan to augment or automate. Metrics can range from hard data points to softer judgment-based evaluations, but everything should be measurable and continuously refined. Complement this with intuitive dashboards to visualize model performance across key initiatives and maintain ongoing transparency.
A robust observability framework evaluates three critical dimensions: retrieval evaluation, response evaluation, and overall workflow evaluation. These dimensions ensure that all aspects of an LLM-powered system operate effectively, delivering accurate and reliable results.
Retrieval Evaluation
Retrieval evaluation focuses on the quality and relevance of data returned by the retriever, particularly in workflows involving RAG (Retrieval-Augmented Generation) systems or proprietary datasets. Key metrics include:
- Recall@K: Measures the proportion of relevant items retrieved out of the total relevant items in the dataset.
- Mean Reciprocal Rank (MRR): Rewards systems that place the first relevant result higher in the retrieval ranking.
- Mean Average Precision (MAP): Evaluates the ranking of multiple relevant results across queries, considering precision at each rank.
- Normalized Discounted Cumulative Gain (NDCG@K): Assigns higher scores to systems prioritizing the most relevant items at the top of the ranking.
- Contextual Precision: Measures the relevancy of retrieved data in the context of the input query and workflow.
- Contextual Recall: Assesses the proportion of relevant information in the expected output that is covered by the retrieval.
- Contextual Relevancy: Calculates the proportion of relevant sentences in the retrieval context to the given input query.
These metrics ensure that retrieval systems provide accurate and contextually relevant data, forming a solid base for subsequent responses or actions.
Response Evaluation
Response evaluation assesses the quality of AI-generated outputs, focusing on user-facing aspects such as clarity, relevance, and factual accuracy. Important metrics include:
- Relevance: Alignment of the response with the user’s query or context.
- Accuracy: Factual correctness of the response, particularly critical in knowledge-intensive applications.
- Clarity: The ease of understanding and logical structuring of the response.
- Groundedness: Verification that the response is based on credible and retrievable sources.
- Engagement: Ability of the response to foster further interaction or achieve intended outcomes.
- Completeness: Ensuring the response addresses all key aspects of the query without omissions.
- Conciseness: Delivery of information efficiently, avoiding unnecessary verbosity.
- Prompt Alignment: Adherence to specific instructions outlined in the input prompt.
- Faithfulness: For RAG workflows, ensuring the generated response aligns with the retrieved context.
- Toxicity and Bias: Detection of harmful, offensive, or biased content.
Evaluation can leverage automated metrics (e.g., BLEU, ROUGE, or embedding-based scores like BERTScore), advanced LLM evaluators (e.g., G-Eval, QAG Score), and human evaluations for nuanced feedback.
Overall Workflow Evaluation
Overall workflow evaluation considers the effectiveness and reliability of the entire system, combining both retrieval and response dimensions while assessing higher-level operational metrics.
- Workflow Latency: Measures the time taken to retrieve data, generate responses, and complete a workflow.
- Workflow Success Rate: The proportion of workflows that achieve the desired end goal without errors or user dissatisfaction.
- User Satisfaction: Evaluates user feedback and ratings for the workflow’s output and process.
- Error Rate: Identifies system failures, such as retrieval inaccuracies, hallucinated responses, or workflow breakdowns.
- Actionability: Determines whether the workflow produces actionable insights or outcomes for the user.
- Adaptability: Assesses how well the workflow adjusts to new queries, inputs, or operational contexts.
These metrics provide a comprehensive view of the workflow's performance, highlighting areas for iteration.
Augment First, Automate Later
Begin by augmenting existing workflows with AI to enhance human capabilities and boost efficiency. Use augmentation as a proving ground to refine systems, build trust, and identify bottlenecks that can be addressed early on. Begin with straightforward, composable patterns such as prompt chaining, routing, and parallelization—systems where large language models (LLMs) follow predefined workflows to deliver consistent, reliable results.
Avoid the temptation to jump into building fully autonomous agentic systems too soon. These systems, which dynamically direct their own processes, can trade off predictability for flexibility and often introduce unnecessary complexity when simpler solutions suffice. Instead, focus on workflows that optimize task-specific performance, leveraging clear input-output paths, validation steps, and programmatic controls.
Once workflows are optimized and teams are confident in their AI systems, you can incrementally transition to more autonomous, adaptive architectures where they provide the greatest value. For example, orchestrator-worker models or evaluator-optimizer loops can handle tasks requiring flexible delegation or iterative refinement. Fully autonomous agents, capable of dynamically adjusting their actions and leveraging environmental feedback, should only be introduced when trust in decision-making and clear success criteria have been established.
This layered approach establishes a strong foundation, allowing teams to address underlying inefficiencies and adapt workflows before prematurely scaling to more complex, independent systems.
For a great read on building LLM workflows and agentic systems, read this post by Anthropic
For Startups and Engineers: Stay Ahead of the Curve
For startups and engineers, staying competitive means focusing relentlessly on the cutting edge of AI, both foundational and applied. The pace of innovation doesn’t wait. If you’re not constantly learning, experimenting, and adapting, you’ll fall behind—and you’ll miss the biggest opportunities to create value and make an impact.
Here’s how to stay ahead
A Hacker Mindset and Experimentation Playgrounds
Start thinking and working like a builder. Being a builder means embracing a mindset of curiosity, creativity, and relentless experimentation. Build things, push their boundaries, break them, and learn from the process. Talk to potential users, gather feedback, and repeat the cycle. Constantly iterate, never settle for "good enough," and hold yourself accountable to a higher standard.
To thrive as a builder, you need environments that enable you to explore advancements and prototype ideas without limitations. These spaces should empower you to:
- Dive into the announcements and releases of newly launched models like o1 and o3. Start building with them as soon as they’re available, experimenting with their capabilities to uncover workflows that were previously unattainable. If access is limited due to a low API usage tier, don’t let that stop you—watch YouTube videos of others experimenting with these models to gain insights and inspiration until your access increases.
- Study open-source projects like Bolt, LLMware, and Onyx to understand how top startups are tackling system design and innovation. Reverse-engineering their frameworks can provide inspiration and practical insights for your own projects.
- Get hands-on with tools like Cursor, v0, Aider, and Bolt, which promote quick iteration and rapid experimentation. These tools allow you to build faster and dive quicker and deeper into emerging ideas.
- Leverage versatile resources to prototype and refine your ideas, such as Jupyter Notebooks for rapid iterations, Google Colabs for cloud-based experimentation, OpenAI’s API Playground for testing and fine-tuning prompts, and Anthropic's Prompt Engineering Library for inspiration and guidance on advanced prompting techniques. For frontend experimentation, tools like v0 are invaluable, providing a seamless way to test and build interfaces.
Build Your Second Brain
Stay ahead by constantly feeding your knowledge and experimentation pipeline:
- Actively track the latest developments, not just by reading but by tinkering (we emphasized the expiermentation playground for a reason —hack away, experiment, and explore firsthand.
- Stay up to date with the latest research in RAG. I personally use this GitHub repo, as well as periodic searches on Google Research and Perplexity.
- Use systems to organize your learning and insights, ensuring you have a living repository of ideas, tools, and resources to reference and build on. I personally handle this idea and tool scratchpad in Notion.
- YouTube, YouTube, YouTube — get premium, trust me it’s worth it. There’s an incredible amount of value available from software engineers, to genAI startup founders, research insitutions, and hackers.
Stay ahead by constantly feeding your knowledge and experimentation pipeline.
- Track the latest developments by doing and engaging, not just reading. The experimentation playground exists for a reason—use it. Hack away, tinker, and explore.
- Stay up to date with research in RAG. I recommend this GitHub repo as a go-to resource, along with periodic deep dives on platforms like Google Research and Perplexity.
- Organize your learning systematically. Use tools like Notion or your preferred platform to create a living repository for ideas, insights, and resources. A well-maintained scratchpad ensures nothing valuable slips through the cracks and keeps you ready to act on new ideas.
- Invest in YouTube as a learning tool. Seriously, get Premium—it’s worth it. The wealth of knowledge shared by software engineers, startup founders, researchers, and hackers is unmatched. I probably watch about 3-4 hours a day.
Go Beyond Frameworks [More Advanced]
While frameworks can accelerate development, they’re inherently reactive. Over-relying on them can hinder your flexibility and limit opportunities to experiment with recent releases. For instance, I’m a big fan of Pydantic AI, a lightweight framework for building agent-driven applications and defined workflows. However, when I needed to experiment with OpenAI’s recent o1 API release, I discovered that Pydantic didn’t yet support it. This posed a critical limitation as the team I was working with was migrating from an o1-mini setup paired with a 4o structured outputs parser to a direct o1 call with structured outputs.
At a minimum, it’s essential to gain extensive experience working directly with the APIs of leading model providers like OpenAI, Anthropic, and Grok, while also exploring open-source providers like Ollama and HuggingFace. Understanding the nuances of these APIs allows you to build more adaptable and flexible solutions.
Moving beyond frameworks requires adopting a modular mindset—integrating only the components that enhance speed without sacrificing flexibility or experimentation. For instance, I’m a big fan of LlamaIndex’s ingestion pipeline and often pair it with a custom-built vector database client. This approach lets me bypass some of the limitations in existing VectorDB interfaces, especially in a rapidly evolving space where new features are released frequently. For advanced engineers, building custom interfaces on top of direct API calls is a crucial step. By leveraging flexible and extensible engineering practices, you ensure that your systems remain adaptable, ready to evolve alongside the pace of emerging technologies.
By building your own tools and internal frameworks, you maintain the ability to continuously experiment, integrate new features as they emerge, and retain complete control over your development process.
The Road Ahead
Applied AI will continue to drive innovation, even in a world dominated by AGI. Progress in this space rewards those who stay curious, experiment relentlessly, and adapt as things evolve. If you’re a founder, engineer, or builder in AI, your advantage lies in thinking like a creator— constantly reading, experimenting with tools, and building systems that deliver value today, and iterating rapidly.
The connection between intelligence and knowledge is what makes applied AI so critical. Intelligence might crack problems, but it’s knowledge that roots it in specific domains. The best applied AI nails this balance, weaving intelligence into workflows where it creates real, measurable impact.
AGI will disrupt mostly everything, but it won’t diminish the need for builders in the applied AI space. Those who stay at the forefront—experimenting, refining, and pushing boundaries—will shape the future. The builders who embrace this mindset will not just adapt to what’s next—they’ll define it.